
Enterprise search can be defined as the systemic approach of retrieving structured and unstructured data from disparate unconnected data sources.
In this blog, we have attempted to demonstrate a use case of leveraging Apache Solr, an open source enterprise search platform, in a news application. The app is an AI curated, multilingual application where user can customize preferences based on source, category, language, and location.
Approach: The following diagram provides a high level architectural view of the solution which was developed to understand the characteristics of search patterns of the end users, and the use of Apache Solr to search content based on the built query so as to provide relevant search results.
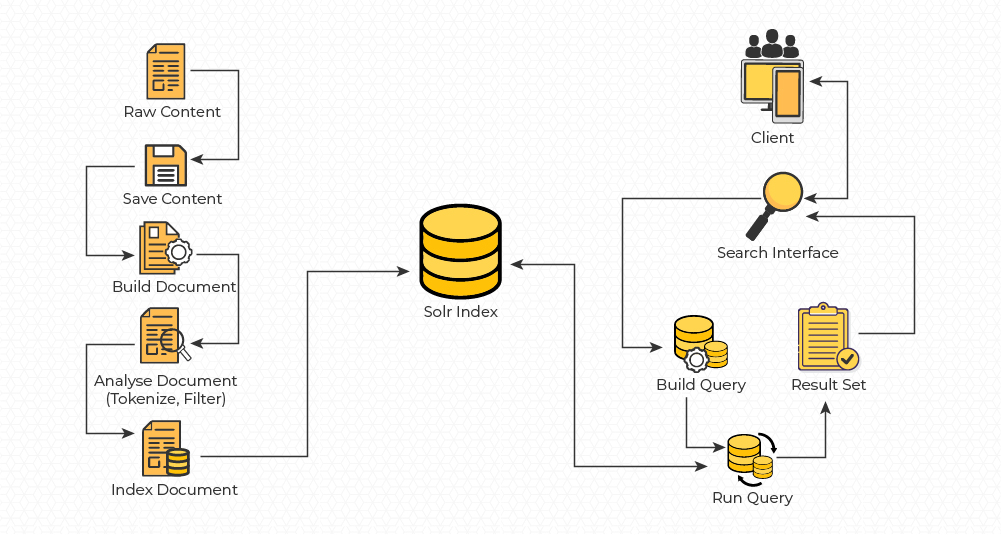
Implementation: Apache Solr is an open source search engine which is built on top of the Java based full-text search engine called Apache LuceneTM. Solr works very well with textual data. It uses the Lucene scoring model to rank documents based on the query parameters configured and returns search results. When a user searches for a news by providing the search text, Solr is designed to ensure that the most relevant match appears first based on the score/rank of documents. The suggestions and autocomplete features strengthen the search capabilities, providing a better user experience.
The news document comprises Headline, Content, Category and multiple Tags. The following steps were performed for indexing and searching.
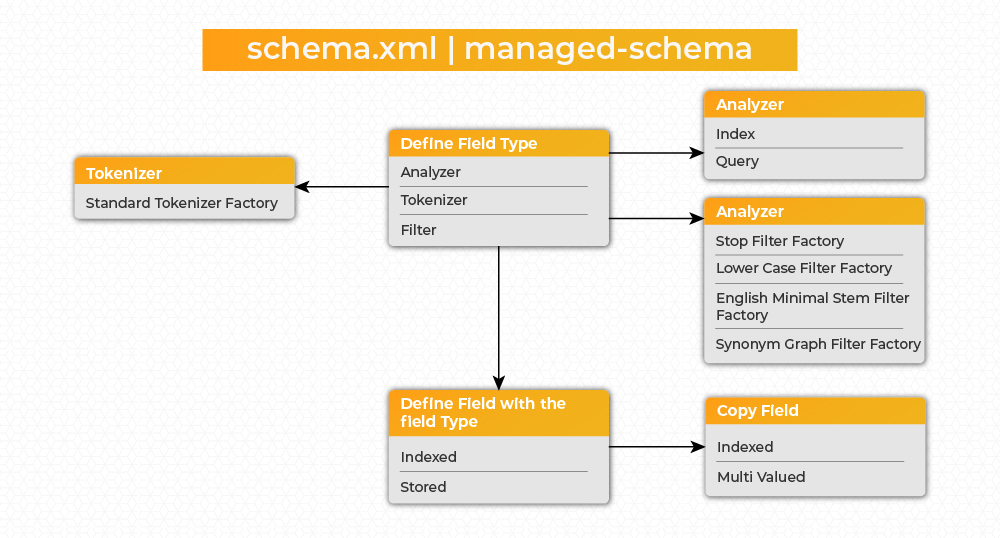
● Indexing involves Analyzers, Tokenizers, and Filters. This is defined for a default/custom field type.
● To define a fieldType (e.g: text_searchable) in schema.xml, provide required analyzers at both ‘index’ and ‘query’ time analysis phases to examine the text and generate a token stream.
● Define headline, content and tags fields with the custom fieldType text_searchable, where the indexed and stored properties are explicitly set to true to make it searchable and retrievable.
● Define a custom field searchField where Solr will copy the above fields to create a multiValued field. The copies are created before analysis is done. The idea is to create a single “search” field that will serve as the default query parameter when users do not specify a field to query. This can be defined as:
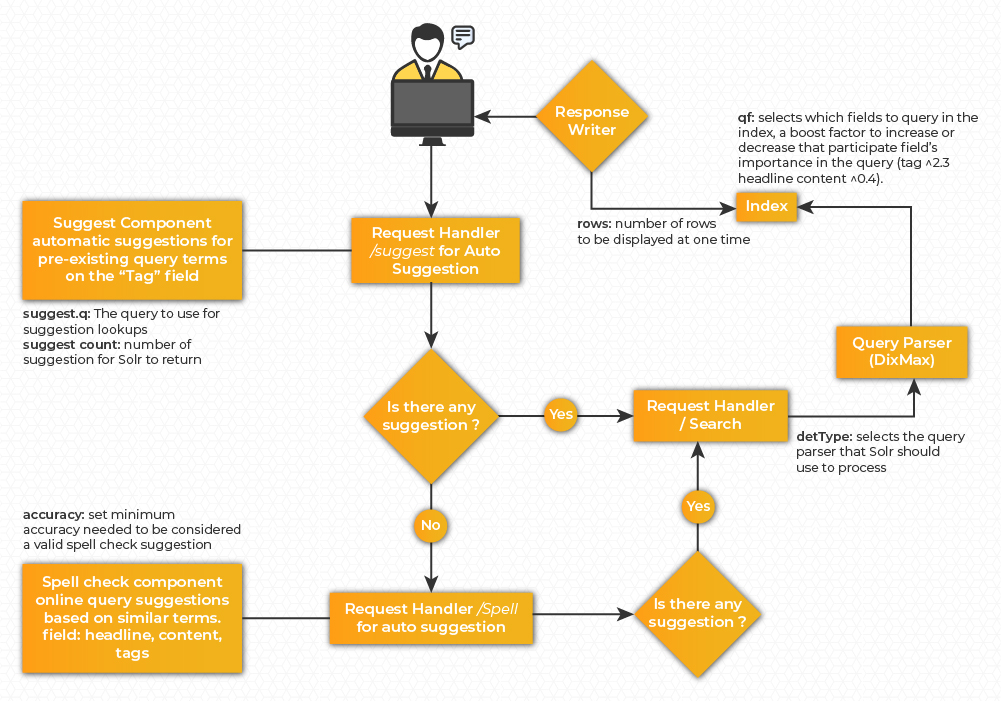
● To provide autocomplete features when user types, these two searchComponents can be used; SuggestComponent and SpellCheckComponent.
● SuggestComponent is used to provide users with automatic suggestions for preexisting query terms. For our use case we have used it on the tags field.
● SpellCheckComponent is used for inline query suggestions based on similar terms. For our use case we have used it on the multivalued field searchField (defined above)
● Once a user selects the required term (from the autocomplete suggestions), Solr will perform the search operation to retrieve the news documents. For that we have updated the search requestHandler to get the news ordered by most relevant ones using the score parameter.
Apache Solr search engine offers a rich, flexible set of features for search. There are many ways to run query completion, we need to adopt the right mechanism and text analysis based on the use case. In this post we have just scratched the surface of Solr’s search capabilities. We will be covering its features in depth in subsequent blogs.




The blog or article is well-written
to render all the important information about apache solr. It’s crisp and encompasses the relevant details which can actually attract non open source community fellows as well. Good Job 👏